The Challenge of Data Quality at Scale
As product catalogs grow into hundreds of thousands or millions of SKUs, maintaining data quality becomes exponentially more challenging. Manual review processes that worked for smaller datasets become impossible to scale, while inconsistencies, outliers, and data errors can significantly impact customer experience and business operations.

Anomaly Detection in Product Data
Example anomaly detection plot showing normal data distribution (black points) with a fitted trend line (green) and potential anomalies that deviate from expected patterns
Traditional rule-based validation can catch basic errors like missing required fields or format violations, but it struggles with contextual anomalies—products that technically meet all rules but still represent data quality issues. This is where AI-powered anomaly detection becomes invaluable, providing intelligent analysis that considers patterns, context, and statistical relationships across your entire product catalog.
Common Data Quality Issues AI Can Detect
- Pricing anomalies: products priced significantly outside category norms
- Dimensional inconsistencies: weight/size relationships that don't align
- Content quality issues: descriptions with negative sentiment or poor formatting
- Category mismatches: products assigned to inappropriate classifications
- Missing critical attributes: gaps in essential product information
- Duplicate or near-duplicate content across different SKUs
Four-attribute section for implementing AI-powered anomaly detection in configurable PIM systems
| Entity | Vendor Name | Description | Key Attributes | Relationships |
|---|---|---|---|---|
Anomaly Status | anomaly_detected | Boolean flag indicating whether an anomaly has been detected for this product | Boolean (true/false) AI auto-updated Triggers workflows | controls visibility in anomaly reports triggers business rule actions |
Anomaly Score | anomaly_score | Numerical score from 0-100 indicating severity of detected anomalies | 0-100 scale Decimal precision Higher = more severe | used for prioritization threshold-based workflow triggers |
Anomaly Attributes | anomaly_attributes | Multi-select list of specific attributes flagged as anomalous | Multi-select list Global list values Maps to attributes | references product attribute names guides remediation efforts |
Anomaly Explanation | anomaly_explanation | AI-generated text explanation describing the detected anomalies and recommended actions | Natural language Actionable tips Multi-language | supports user understanding enables informed decision-making |
"This anomaly detection approach is absolutely feasible and aligns perfectly with modern PIM architectures. Struct's Azure-native platform with configurable Product Structures and Business Rules engine makes it an ideal candidate, but the same principles work across any PIM system with webhook capabilities and flexible data modeling. The key is leveraging the PIM's existing business logic while adding AI intelligence on top."
Implementation Approach
Architecture Overview
The anomaly detection system follows a hybrid architecture that combines PIM-native business rules with external AI processing. This approach leverages the PIM system's existing data validation and workflow capabilities while adding sophisticated AI analysis for pattern recognition and anomaly scoring.
Three Implementation Pathways
Option A: Webhook-Driven Real-Time Analysis
Configure PIM webhooks to trigger on product create/update events. External Azure Functions receive webhook payloads, analyze product data using Azure AI services, and update anomaly attributes via the PIM API. Best for systems requiring immediate anomaly detection.
Option B: Business Rules Integration
Extend existing PIM business rules to make HTTP calls to Azure AI endpoints during product processing. AI analysis results are directly incorporated into business rule logic, enabling immediate workflow actions. Ideal for PIM systems with robust business rule engines.
Option C: Scheduled Batch Processing
Implement periodic bulk analysis using PIM API batch operations. Azure AI services analyze large product datasets during off-peak hours, updating anomaly scores and explanations in batches of up to 5,000 products. Most suitable for performance-sensitive environments.
AI Service Integration
The system utilizes multiple Azure AI services for comprehensive anomaly detection:
- Azure Machine Learning: Custom anomaly detection models trained on your specific product data patterns
- Azure Cognitive Services: Text analysis for content quality assessment and sentiment analysis
- Azure OpenAI: Natural language generation for human-readable anomaly explanations
- Azure AI Search: Semantic similarity detection for identifying duplicate or near-duplicate content
API Implementation Example
Example showing bulk anomaly analysis update using PIM API with anomaly detection results
# Bulk anomaly detection results update
$apikey = "<api_key>"
$anomalyResults = @(
@{
id = 98765;
attributes = @{
anomaly_detected = $true;
anomaly_score = 87;
anomaly_attributes = @("price", "description", "weight");
anomaly_explanation = "Price 300% above category average (€299 vs €89 typical). Description contains negative sentiment indicators. Weight-to-dimension ratio suggests data entry error."
}
},
@{
id = 98766;
attributes = @{
anomaly_detected = $false;
anomaly_score = 12;
anomaly_attributes = @();
anomaly_explanation = "No significant anomalies detected. All attributes within expected ranges."
}
}
) | ConvertTo-Json -Depth 3
Invoke-RestMethod -Uri "https://acme.struct.com/api/products" `
-Method Patch `
-Headers @{"x-api-key"=$apikey; "Content-Type"="application/json"} `
-Body $anomalyResultsPIM System Requirements
This anomaly detection approach can be implemented across any modern PIM system that provides the necessary technical foundation for AI integration.
Essential Requirements
API Access: The PIM system must provide REST API capabilities for reading product data and updating anomaly attributes. Most modern PIM platforms offer comprehensive API access that supports bulk operations and real-time data synchronization.
Configurable Data Model: The ability to add custom attributes or sections to product records is essential for storing anomaly detection results. This includes boolean fields, numerical scores, multi-select lists, and text fields for explanations.
Webhook or Event System: For real-time anomaly detection, the PIM should support webhooks or event triggers that can notify external systems when products are created or modified.
Leveraging Built-in AI Capabilities
Many modern PIM systems now include built-in AI assistants and content generation features. These native AI capabilities can be leveraged alongside or instead of external AI services:
- Content Analysis: Built-in AI can analyze product descriptions, titles, and other text content for quality issues and inconsistencies
- Data Validation: AI assistants can help identify missing or incomplete product information based on category requirements
- Automated Scoring: Some platforms offer configurable scoring systems that can be enhanced with AI-generated quality assessments
- Pattern Recognition: Native AI features can learn from user corrections and improve anomaly detection accuracy over time
The key advantage of using built-in AI capabilities is seamless integration without external dependencies, though the sophistication may be limited compared to specialized AI services.
Explore complementary approaches to enhance your PIM implementation with AI and strategic frameworks



Performance & Scalability Considerations
Processing Volume Guidelines
Different implementation approaches handle varying volumes of product data with different performance characteristics:
- Real-time Processing: Suitable for up to 1,000 product updates per hour with sub-minute latency requirements
- Near Real-time: Handles 5,000-10,000 updates per hour with 5-15 minute processing delays
- Batch Processing: Optimized for 100,000+ products with daily or hourly analysis cycles
Cost Optimization Strategies
Azure AI service costs can be managed through several approaches:
- Tiered Analysis: Apply basic rule-based validation first, then AI analysis only for products that pass initial filters
- Sampling Strategies: Analyze representative product samples for pattern identification, then apply learned patterns more broadly
- Threshold-Based Processing: Focus AI analysis on products with recent changes or above certain value thresholds
- Regional Optimization: Deploy AI services in regions with optimal pricing for your data residency requirements
Integration Architecture
For optimal performance, implement a middleware layer that handles:
- API rate limiting and retry logic
- Caching of AI analysis results
- Asynchronous processing queues
- Error handling and logging
- Result aggregation and reporting
Business Benefits & ROI
Quantifiable Improvements
Organizations implementing AI-powered anomaly detection typically see measurable improvements across several key areas:
- Data Quality: 60-80% reduction in data quality issues reaching customers
- Manual Review Time: 70-90% decrease in time spent on manual product data validation
- Customer Experience: Significant reduction in support tickets related to incorrect product information
- Operational Efficiency: Faster time-to-market for new products with automated quality assurance
Risk Mitigation
Automated anomaly detection helps prevent costly issues:
- Pricing Errors: Catch pricing anomalies before they impact revenue or customer trust
- Compliance Issues: Identify missing or incorrect regulatory information before products go live
- Brand Protection: Detect content quality issues that could harm brand reputation
- Supply Chain Disruptions: Flag dimensional or specification errors that could cause fulfillment problems
Competitive Advantages
Beyond operational improvements, anomaly detection provides strategic benefits:
- Market Intelligence: Identify pricing patterns and competitive positioning anomalies
- Product Portfolio Optimization: Detect underperforming or mispositioned products
- Customer Insights: Understand which product attributes most commonly contain errors
- Scalability: Maintain data quality standards as product catalogs grow exponentially
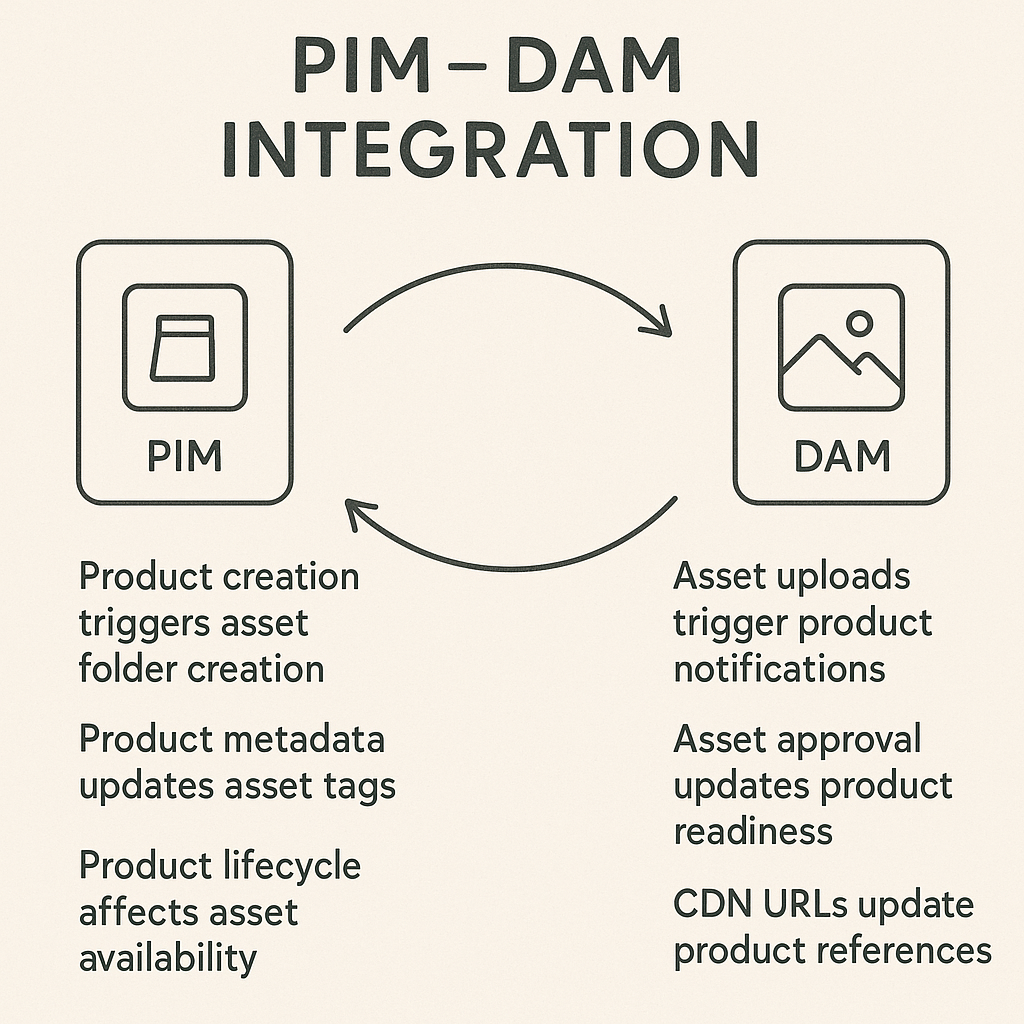
Learn more about PIM systems and implementation approaches to support your anomaly detection strategy

Getting Started with PIM Anomaly Detection
Implementing AI-powered anomaly detection in your PIM system is a strategic investment that pays dividends through improved data quality, reduced manual effort, and enhanced customer experience. The key to success is starting with a focused pilot program that demonstrates value before scaling to your entire product catalog.
Recommended Implementation Phases
Phase 1: Proof of Concept (2-4 weeks)
Select a representative product subset (1,000-5,000 SKUs) from a single category. Implement basic anomaly detection for pricing and content quality. Measure baseline data quality metrics and establish success criteria.
Phase 2: Pilot Program (1-2 months)
Expand to multiple product categories with full anomaly attribute implementation. Integrate with existing PIM workflows and train team members on anomaly review processes. Refine AI models based on domain expertise.
Phase 3: Full Deployment (3-6 months)
Roll out across entire product catalog with optimized performance architecture. Implement advanced analytics and reporting dashboards. Establish ongoing monitoring and continuous improvement processes.
Ready to transform your product data quality with AI-powered anomaly detection? Contact our PIM implementation experts to discuss your specific requirements and develop a customized implementation roadmap.